
这个现实世界造成了很多挑战,比如数据有限、只有微型的计算机硬件(像手机、树莓派)所造成的无法运行复杂深度学习模型等。这篇文章演示了如何使用树莓派来进行目标检测。就像路上行驶的汽车,冰箱里的橘子,文件上的签名和太空中的特斯拉。
免责声明:我正在建设 nanonets.com 来帮助使用很少的数据和没有计算机硬件的情况下构建机器学习模型。
如果你很迫切,请直接下拉到这篇文章的底部进入Github的仓库。
为什么是目标检测?为什么是树莓派?
树莓派是一款灵活的计算机硬件,它以1500万台的销量已经吸引了一代消费者的心,并且黑客们也在树莓派上构建了很多很酷的项目。考虑到深度学习和树莓派相机的的流行,我们认为如果能在树莓派上使用深度学习来检测任意的物体那就非常棒了。
现在你可以检测到你的自拍照里的照片炸弹,有人进入到Harambe的笼子里,哪里有辣椒酱或者亚马逊的快递员进入到你的房子里。
什么是目标检测?
2000万年的进化使得人类的视觉系统有了相当高的进化。人脑有30%的神经元负责处理视觉信息(相对比只有8%处理触觉和3%处理听觉)。与机器相比,人类有两个主要的优势。一是立体视觉,二是训练数据集的供应几乎是无限的(一个五岁的婴儿可以大约在30fps的采样间隔获得2.7B的图像数据)。

为了模仿人类水平的表现,科学家将视觉感知任务分解为四个不同的类别。
1.分类,为图像指定一个标签。
2.定位,对特定的标签指定一个边框。
3.物体检测,在图像中绘制多个边框。
4.图像分割,得到物体在图像中的精确位置区域。
物体检测对于很多应用已经足够好(图像分割是更精确的结果,它受到了创建训练数据复杂性的影响。相比于画边框它通常花费人类标注者12倍的时间去分割图像。)此外,在检测物体之后,可以将物体在边框中单独分割出来。
使用物体检测:
目标检测具有重要的现实意义,已经在各行各业得到了广泛应用。下面列举了一些例子:

我怎样使用物体检测解决自己的问题?
物体检测可以用于解决各种各样的问题。这些是一个概括的分类:
1.物体是不是出现在我的图像中?比如在我的房子有一个入侵者。
2.在图像中的一个物体在哪个位置?比如一个汽车试图在世界各地导航时,知道物体的位置就很重要。
3.图像中有多少个物体?物体检测是计算物体数目最有效的方法之一。比如仓库的货架上有多少个盒子。
4.图像中有哪些不同类型的物体?比如动物园的哪些区域有哪些动物?
5.物体的尺寸有多大?特别是使用静态的相机,很容易计算出物体的大小。比如芒果的大小是多少。
6.物体之间是如何相互作用的?比如在足球场上的队形是如何影响比赛结果的?
7.物体在不同时间的位置(跟踪一个物体)?比如跟踪一个像火车一样的物体并且计算它的速度。
在20行代码内完成物体检测
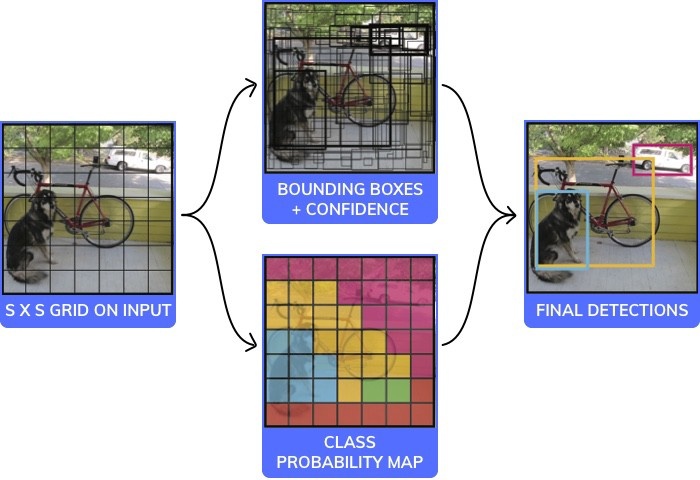
YOLO算法的可视化
有多种用于物体检测的模型或结构。每一个都在速度、尺寸和精确度之间权衡。我们选择了最流行的一个:YOLO(You only look once),并且展示它如何以20行代码(忽略注释)进行工作。
注意:这是伪代码,不是一个可直接工作的实例。它有一个非常标准的CNN构成的黑箱,如下图所示:
你可以阅读(YOLO)全文:
https://pjreddie.com/media/files/papers/yolo_1.pdf
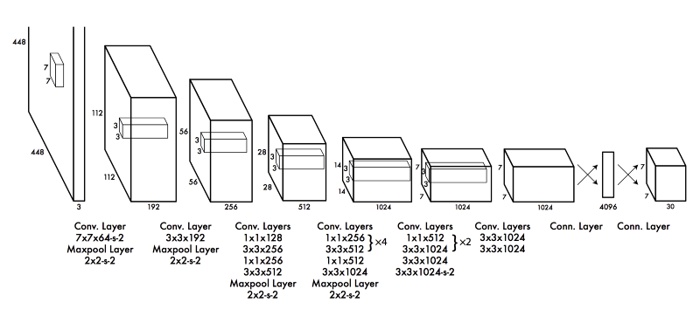
YOLO中使用卷积神经网络的体系结构代码小于20行,如下:
#this is an Image of size 140x140. We will assume it to be black and white (ie only one channel, it would have been 140x140x3 for rgb)
image = readImage()
#We will break the Image into 7 coloumns and 7 rows and process each of the 49 different parts independently
NoOfCells = 7
#we will try and predict if an image is a dog, cat, cow or wolf. Therfore the number of classes is 4
NoOfClasses = 4
threshold = 0.7
#step will be the size of step to take when moving across the image. Since the image has 7 cells step will be 140/7 = 20
step = height(image)/NoOfCells
#stores the class for each of the 49 cells, each cell will have 4 values which correspond to the probability of a cell being 1 of the 4 classes
#prediction_class_array[i,j] is a vector of size 4 which would look like [0.5 #cat, 0.3 #dog, 0.1 #wolf, 0.2 #cow]
prediction_class_array = new_array(size(NoOfCells,NoOfCells,NoOfClasses))
#stores 2 bounding box suggestions for each of the 49 cells, each cell will have 2 bounding boxes, with each bounding box having x, y, w ,h and c predictions. (x,y) are the coordinates of the center of the box, (w,h) are it's height and width and c is it's confidence
predictions_bounding_box_array = new_array(size(NoOfCells,NoOfCells,NoOfCells,NoOfCells))
#it's a blank array in which we will add the final list of predictions
final_predictions = []
#minimum confidence level we require to make a prediction
threshold = 0.7
for (i<0; i<NoOfCells; i=i+1):
for (j<0; j<NoOfCells;j=j+1):
#we will get each "cell" of size 20x20, 140(image height)/7(no of rows)=20 (step) (size of each cell)"
#each cell will be of size (step, step)
cell = image(i:i+step,j:j+step)
#we will first make a prediction on each cell as to what is the probability of it being one of cat, dog, cow, wolf
#prediction_class_array[i,j] is a vector of size 4 which would look like [0.5 #cat, 0.3 #dog, 0.1 #wolf, 0.2 #cow]
#sum(prediction_class_array[i,j]) = 1
#this gives us our preidction as to what each of the different 49 cells are
#class predictor is a neural network that has 9 convolutional layers that make a final prediction
prediction_class_array[i,j] = class_predictor(cell)
#predictions_bounding_box_array is an array of 2 bounding boxes made for each cell
#size(predictions_bounding_box_array[i,j]) is [2,5]
#predictions_bounding_box_array[i,j,1] is bounding box1, predictions_bounding_box_array[i,j,2] is bounding box 2
#predictions_bounding_box_array[i,j,1] has 5 values for the bounding box [x,y,w,h,c]
#the values are x, y (coordinates of the center of the bounding box) which are whithin the bounding box (values ranging between 0-20 in your case)
#the values are h, w (height and width of the bounding box) they extend outside the cell and are in the range of [0-140]
#the value is c a confidence of overlap with an acutal bounding box that should be predicted
predictions_bounding_box_array[i,j] = bounding_box_predictor(cell)
#predictions_bounding_box_array[i,j,0, 4] is the confidence value for the first bounding box prediction
best_bounding_box = [0 if predictions_bounding_box_array[i,j,0, 4] > predictions_bounding_box_array[i,j,1, 4] else 1]
# we will get the class which has the highest probability, for [0.5 #cat, 0.3 #dog, 0.1 #wolf, 0.2 #cow], 0.5 is the highest probability corresponding to cat which is at position 0. So index_of_max_value will return 0
predicted_class = index_of_max_value(prediction_class_array[i,j])
#we will check if the prediction is above a certain threshold (could be something like 0.7)
if predictions_bounding_box_array[i,j,best_bounding_box, 4] * max_value(prediction_class_array[i,j]) > threshold:
#the prediction is an array which has the x,y coordinate of the box, the height and the width
prediction = [predictions_bounding_box_array[i,j,best_bounding_box, 0:4], predicted_class]
final_predictions.append(prediction)
print final_predictions
如何建立目标检测的深度学习模型?
深度学习的工作流程有6个基本步骤,分为了三个部分:
1.收集训练集
2.训练模型
3.预测新图像
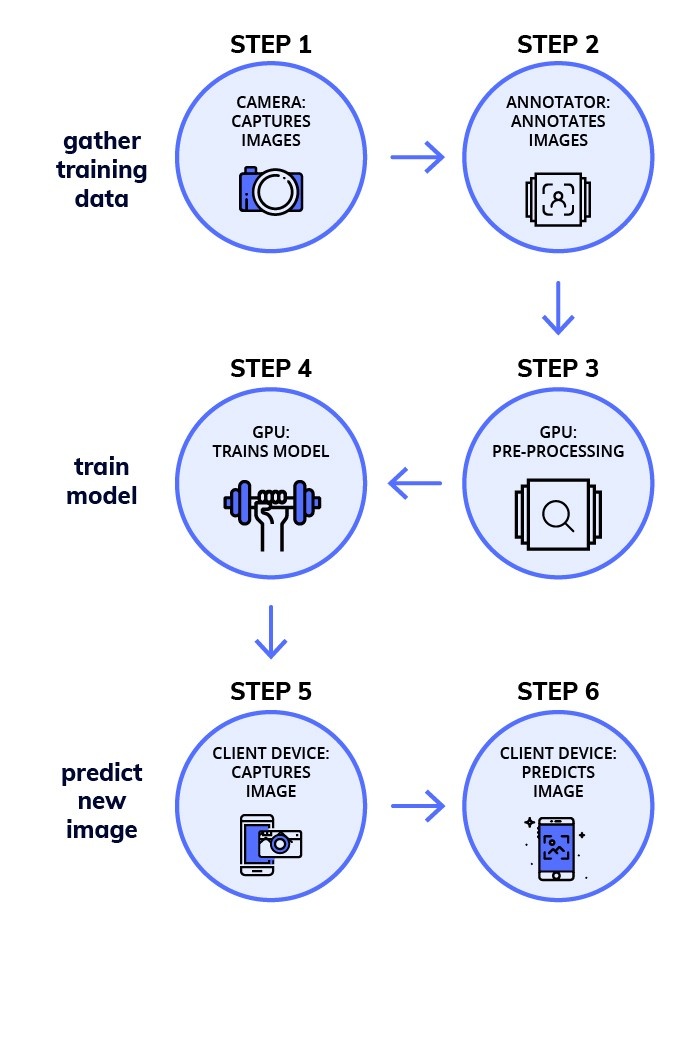
第1阶段 — 收集训练数据
步骤1. 收集图像(每个对象至少100张)
对于这个任务,你或许需要为每个对象收集100张图像。尽量捕捉与将用于决策的数据关联性更强的图像。

步骤2. 注释(手动在图像上绘制边框)
在图像上绘制边界框。 您可以使用 labelImg 之类的工具。 你通常需要一些人来为你的图像注释。 这是一项相当耗时的任务。

第二阶段——在一个有GPU的机器上训练模型
步骤3. 为迁移学习找到一个预训练好的模型:
关于这些你可以阅读更多内容medium.com/nanonets/nanonets-how-to-use-deep-learning-when-you-have-limited-data-f68c0b512cab。为了减少训练所需的数据量,你需要一个预训练好的模型。如果没有它,你可能多需要10万张图像来训练模型。
步骤4. 在GPU上进行训练(像AWS/GCP之类的云服务或者你自己的具有GPU机器):

Docker Image
训练模型的过程是很难进行简化的,我们创建了docker image来使模型更容易训练。
你可以运行以下代码开始训练模型:
sudo nvidia-docker run -p 8000:8000 -v `pwd`:data docker.nanonets.com/pi_training -m train -a ssd_mobilenet_v1_coco -e ssd_mobilenet_v1_coco_0 -p '{"batch_size":8,"learning_rate":0.003}'
docker image具有一个run.sh脚本,可以用以下参数来调用它:
run.sh [-m mode] [-a architecture] [-h help] [-e experiment_id] [-c checkpoint] [-p hyperparameters] -h display this help and exit -m mode: should be either `train` or `export` -p key value pairs of hyperparameters as json string -e experiment id. Used as path inside data folder to run current experiment -c applicable when mode is export, used to specify checkpoint to use for export
你可以在以下网站找到更多详细信息:
NanoNets/RaspberryPi-ObjectDetection-TensorFlow
为了训练模型你需要选择正确的超参数。
寻找正确的超参数
“深度学习”的技巧就是计算出使模型最准确时最好的参数。与此相关的在一定程度上像是黑魔法,但是还有一些理论。这是找到正确参数很好的资源。
量化模型(使模型更小以适应于像树莓派和手机这样的小设备)
像手机和树莓派这样的小设备有很小的内存和计算能力。
通过对权重的很多微调来完成神经网络的训练,而且这项工作需要这些小的增量通常要达到浮点精度(尽管这里也在努力研究使用量化模型表示)。
采用一个预训练好的模型和运行推理是非常不同的。深度的神经网络一个非常神奇的优点就是往往能够更好的处理输入中的高噪声。
为什么要量化?
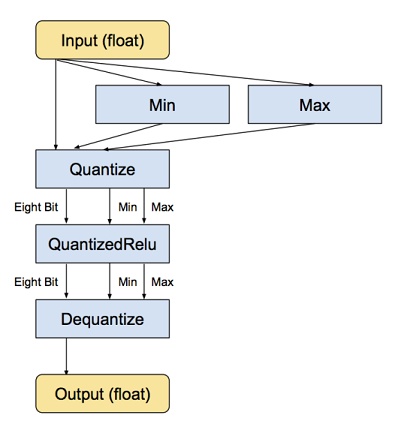
神经网络模型会占用磁盘的大量空间,例如最初的AlexNet模型以浮点格式超过200MB,占用的空间大小几乎都是由连接神经元的权重决定的,因为在一个简单模型中通常有超过数百万个权重。
神经网络的节点和权重最初是存储为32位的浮点数。量化模型最简单的一个做法就是通过存储每一层最小和最大的值来压缩文件的大小,接着压缩每一个浮点数为8位整型。这样文件的大小就减少了75%。
量化模型的代码:
curl -L "https://storage.googleapis.com/download.tensorflow.org/models/inception_v3_2016_08_28_frozen.pb.tar.gz" |
tar -C tensorflow/examples/label_image/data -xz
bazel build tensorflow/tools/graph_transforms:transform_graph
bazel-bin/tensorflow/tools/graph_transforms/transform_graph \
--in_graph=tensorflow/examples/label_image/data/inception_v3_2016_08_28_frozen.pb \
--out_graph=/tmp/quantized_graph.pb \
--inputs=input \
--outputs=InceptionV3/Predictions/Reshape_1 \
--transforms='add_default_attributes strip_unused_nodes(type=float, shape="1,299,299,3")
remove_nodes(op=Identity, op=CheckNumerics) fold_constants(ignore_errors=true)
fold_batch_norms fold_old_batch_norms quantize_weights quantize_nodes
strip_unused_nodes sort_by_execution_order
注意:我们的 docker image 内置量化。
第三阶段:使用树莓派对新图像进行预测
步骤5:通过相机捕捉新图像
你需要树莓派的相机开启和工作,接着捕获一张新图像。

关于怎样安装的说明请点击这里
import picamera, os
from PIL import Image, ImageDraw
camera = picamera.PiCamera()
camera.capture('image1.jpg')
os.system("xdg-open image1.jpg")
捕获新图像的代码
步骤6:预测一张新图像
下载模型
一旦你完成了模型的训练,你就可以把它下载到你的树莓派上了。导入模型运行以下代码:
sudo nvidia-docker run -v `pwd`:data docker.nanonets.com/pi_training -m export -a ssd_mobilenet_v1_coco -e ssd_mobilenet_v1_coco_0 -c /data/0/model.ckpt-8998
接着将模型下载到树莓派上。
在树莓派上安装TensorFlow
根据设备的不同,你可能需要更改一些安装方式。
sudo apt-get install libblas-dev liblapack-dev python-dev libatlas-base-dev gfortran python-setuptools libjpeg-dev sudo pip install Pillow sudo pip install http://ci.tensorflow.org/view/Nightly/job/nightly git clone https://github.com/tensorflow/models.git sudo apt-get install -y protobuf-compiler cd models/research/ protoc object_detection/protos/*.proto --python_out=. export PYTHONPATH=$PYTHONPATH:/home/pi/models/research:/home/pi/models/research/slim
运行预测新图像的模型
python ObjectDetectionPredict.py --model data/0/quantized_graph.pb --labels data/label_map.pbtxt --images /data/image1.jpg /data/image2.jpg
在树莓派上的性能基准
树莓派受限于内存和计算力(与树莓派GPU兼容的TensorFlow版本仍然不可用)。因此,衡量每个模型在对新图片进行预测花费的时间很重要。

在树莓派上运行的不同的物体检测模型的基准
使用NanoNets的工作流程:
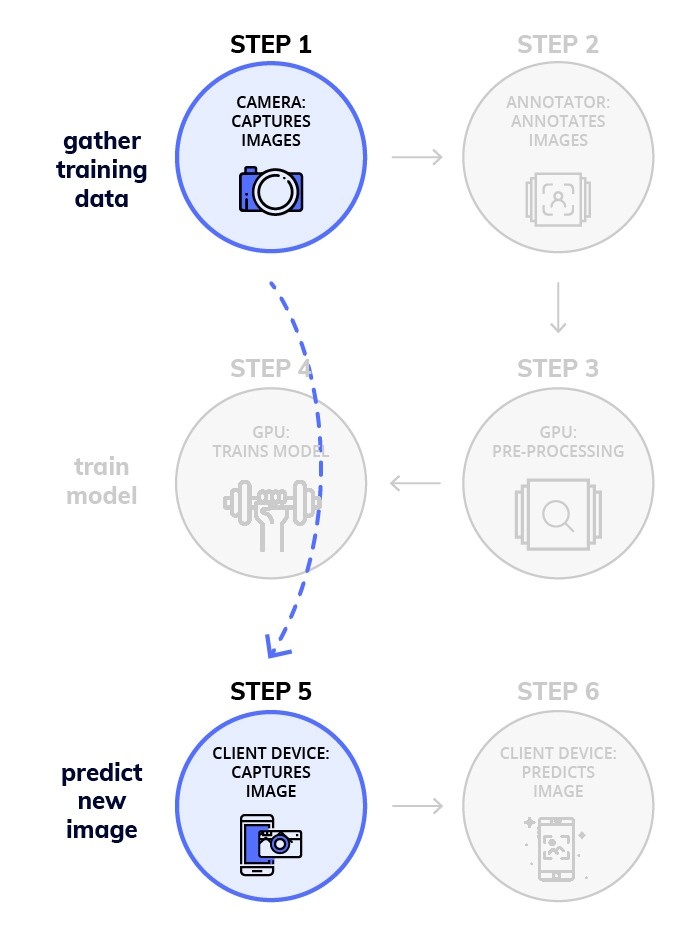
我们对于NanoNets的一个目标就是使我们的工作能够很容易的与深度学习结合。物体检测是我们重点关注的一个领域,并且我们制定了一个工作流程可以解决一些实现深度学习模型的挑战。
NanoNets怎样使过程更简单?
1.不需要注释
我们已经删除了注释图像的需要,我们有专业的注释员可以为你注释图像。
2.自动进行最优模型和超参数的选择
我们为你自动的训练最好的模型,通过运行一连串具有不同参数的模型然后为你的数据挑选最好的那个。
3.不需要昂贵的硬件和GPUs
NanoNets完全在云端运行,不需要占用你的任何硬件。这样就会更容易去使用。
4.对于像树莓派这样的移动设备非常棒
因为像树莓派和手机这样的设备不适用于运行复杂的计算任务,所以可以将你的工作负载外包给我们的云,然后为你完成所有的计算。
这里是一个简单的片段使用NanoNets API进行图像的预测
import picamera, json, requests, os, random
from time import sleep
from PIL import Image, ImageDraw
#capture an image
camera = picamera.PiCamera()
camera.capture('image1.jpg')
print('caputred image')
#make a prediction on the image
url = 'https://app.nanonets.com/api/v2/ObjectDetection/LabelFile/'
data = {'file': open('image1.jpg', 'rb'), \
'modelId': ('', 'YOUR_MODEL_ID')}
response = requests.post(url, auth=requests.auth.HTTPBasicAuth('YOUR_API_KEY', ''), files=data)
print(response.text)
#draw boxes on the image
response = json.loads(response.text)
im = Image.open("image1.jpg")
draw = ImageDraw.Draw(im, mode="RGBA")
prediction = response["result"][0]["prediction"]
for i in prediction:
draw.rectangle((i["xmin"],i["ymin"], i["xmax"],i["ymax"]), fill=(random.randint(1, 255),random.randint(1, 255),random.randint(1, 255),127))
im.save("image2.jpg")
os.system("xdg-open image2.jpg")
使用NanoNets进行图像预测的代码
建立你自己的NanoNet
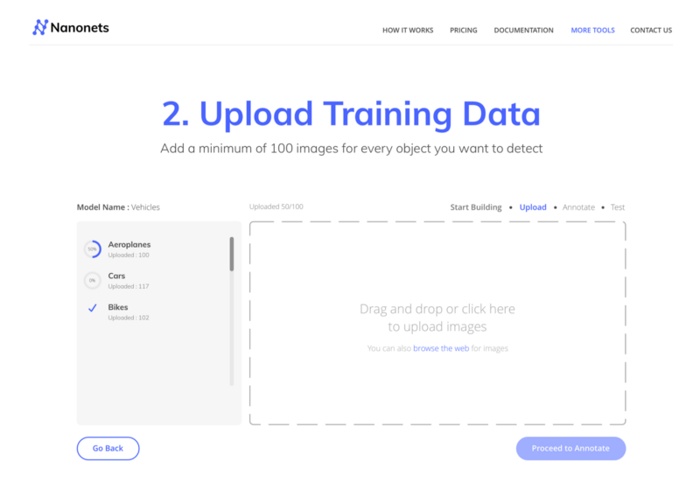
你可以尝试建立你自己的模型:
1.使用一个GUI(也自动的注释图像):
https://nanonets.com/objectdetection/
2.使用我们的API:
https://github.com/NanoNets/object-detection-sample-python
步骤1:克隆这个仓库
git clone cd object-detection-sample-python sudo pip install requests
步骤2:获取你免费的API钥匙
从这里得到你免费的API钥匙 http://app.nanonets.com/user/api_key
步骤3:设置API钥匙作为一个环境变量
export NANONETS_API_KEY=YOUR_API_KEY_GOES_HERE
步骤4:创建一个新模型
python ./code/create-model.py
注意:这里生成你下一步需要的MODEL_ID
步骤5:增加模型ID为环境变量
export NANONETS_MODEL_ID=YOUR_MODEL_ID
步骤6:上传训练数据
收集你需要检测的物体的图像。你可以通过我们的网站UI(https://app.nanonets.com/ObjectAnnotation/?appId=YOUR_MODEL_ID)
标注它们任何一个或者使用像 labelImg 这样的开源工具。一旦你在文件夹。
准备好数据,images(图像文件)、annotations (图像文件的标注),开始上传数据集。
python ./code/upload-training.py
步骤7:训练模型
一旦图像上传完成就开始训练模型
python ./code/train-model.py
步骤8:获取模型状态
这个模型大约要花2个小时进行训练,一旦模型开始训练,你将收到一封电子邮件,同时可以查看模型的状态。
watch -n 100 python ./code/model-state.py
步骤9:做预测
一旦模型训练完毕,你就可以使用模型进行预测
python ./code/prediction.py PATH_TO_YOUR_IMAGE.jpg
代码(Github仓库)
训练模型的GitHub仓库:
Tensorflow Code for model Training and Quantization
NanoNets Code for model Training
使用树莓派进行预测的GitHub仓库(以检测新目标为例):
Tensorflow Code for making Predictions on the Raspberry Pi
NanoNets Code for making Predictions on the Raspberry Pi
带标注的数据集:
Cars on Indian Roads sees, dataset for extracting vehicles from Images of Indian Roads
Coco Dataset
via
发起:酱番梨 校对:老赵 审核:老赵
参与翻译(2人):小哥哥、狒狒

每次得要通过网络上传图片得到结果,对实时的目标检测会不会有点慢?
遇到问题了,可以帮忙指导一下吗?可以付一定的指导费,邮件联系,谢谢!
你好请问你得到了问题的指导了么
步骤4:创建一个新模型
1
python ./code/create-model.py
注意:这里生成你下一步需要的MODEL_ID
步骤5:增加模型ID为环境变量
1
export NANONETS_MODEL_ID=YOUR_MODEL_ID
请问在第四步报Traceback (most recent call last):
File “F:\pycharm_code\Pedestrian-Detection-master\nanonets\code\create-model.py”, line 11, in
model_id = json.loads(response.text)[“model_id”]
KeyError: ‘model_id’
这样的错是怎么回事呢,怎么解决呢?
请问有完整代码或指导视频教程吗?
網絡最好的地方能讓很多人利用空間資源對科技出一分力量
效果展示 https://v.youku.com/v_show/id_XNDc5NTMyODgyOA==.html