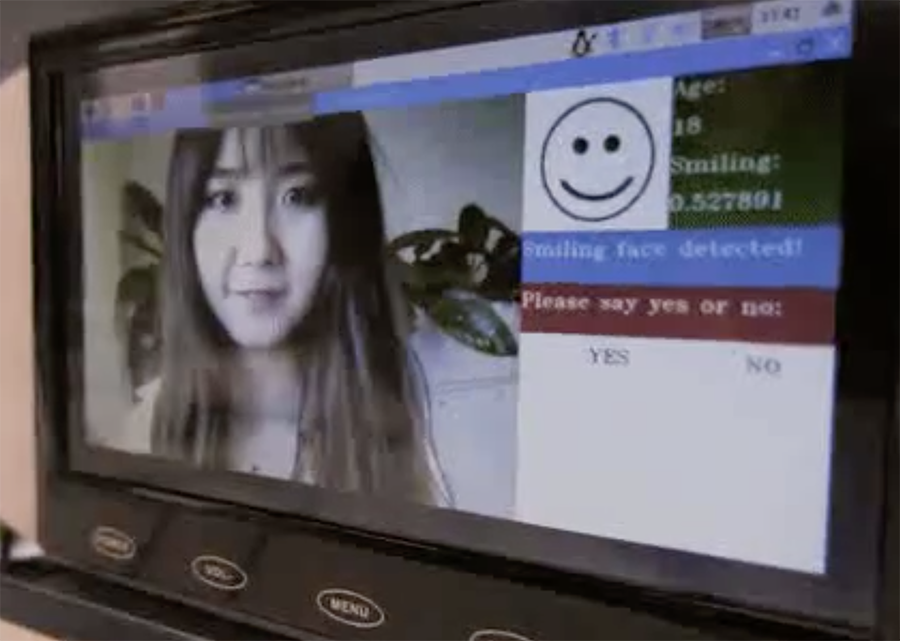
我们很高兴展示借助 TensorFlow Lite 在 Raspberry Pi 上构建 Smart Photo Booth 应用的经验(我们尚未开放源代码)。该应用可以捕捉笑脸并自动进行记录。此外,您还可以使用语音命令进行交互。简而言之,借助 Tensorflow Lite 框架,我们构建出可实时轻松处理笑脸检测和识别语音命令的应用。
为什么选择 Raspberry Pi?
Raspberry Pi 不仅是使用广泛的嵌入式平台,且有体积小、价格便宜的优势。我们选择 TensorFlow Lite 是因为它专为移动端和 IoT 设备而设计,因此非常适合 Raspberry Pi。
构建 Photo Booth 应用需准备什么?
我们已在 Raspberry Pi 3B+ 上实现 Photo Booth 应用,其搭载 1GB RAM,并装有 32 位 ARMv7 操作系统。我们的应用具有图像输入和音频输入功能,因此我们还需要摄像头和麦克风。除此之外,我们还需要显示器来显示内容。总成本不到 100 美元。详情如下所列:

一台 Raspberry Pi(35 美元)
配置:
» 主频为 1.4GHz 的四核 64 位处理器
» 1GB LPDDR2 SRAM
一部用于捕获图像的摄像头(约 15 美元)
一个采集音频数据的麦克风(约 5 美元)
一台 7 英寸的显示器(约 20 美元)
Photo Booth 应用涉及到两个关键技术:
1、我们需要从相机的图像输入中检测是否有笑脸;
2、我们需要从麦克风的音频输入中识别出是否存在“是”或“否”的语音命令。
如何检测笑脸?
我们很难在使用单个模型检测人脸并预测笑脸得分结果的同时保证高精度和低延迟。因此,我们通过以下三个步骤来检测笑脸:
1、应用人脸检测模型来检测给定的图像中是否存在人脸。
2、如果存在,则将其从原始图像中裁剪出来。
3、对裁剪后的人脸图像应用人脸属性分类模型,以测量其是否为笑脸。
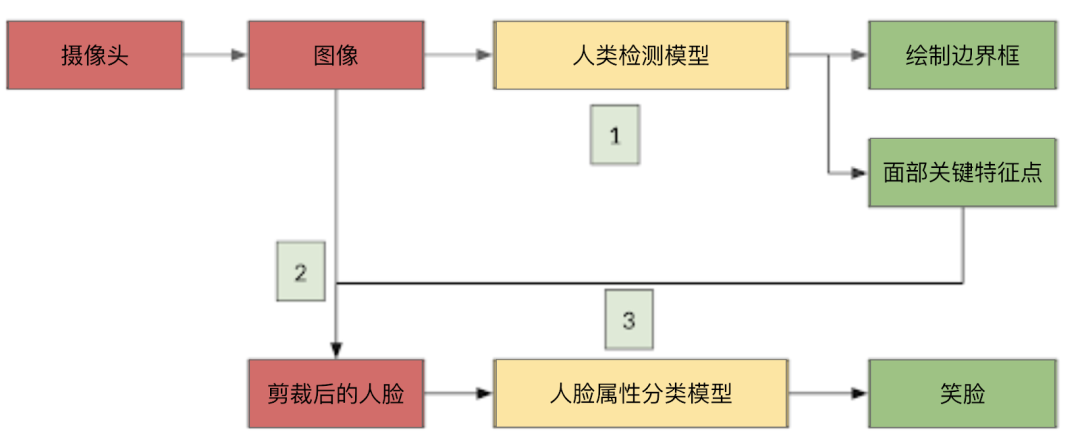
笑脸检测工作流
我们尝试了如下几种方法来降低笑脸检测的延迟时间:
1、为减少内存占用并加速执行进程,我们使用了 TensorFlow 模型优化工具包中的训练后量化 (Post Training Quantization) 技术。在本教程中,针对您自己的 TensorFlow Lite 模型,您会发现该技术将非常易于使用。
2、对从摄像头中捕获的原始图像进行大小调整,并固定其长宽比。压缩率根据原始图像大小采用 4 或 2。尽量让图像尺寸小于 160×160(原设计尺寸为 320×320)。输入尺寸较小的图像可以大大减少推理时间,如下表所示。在我们的应用中,从相机中捕获的原始图像尺寸为 640×480,所以我们将图像尺寸调整为 160×120。
3、我们并未使用原始图像进行面部属性分类,而是弃用背景并使用裁剪出的标准人脸。如此可在保留有用信息的同时减小输入图像的尺寸。
4、使用多线程开展推理
下表显示我们所用策略所带来的效果。我们使用 Tensorflow Lite 模型性能测试工具对人脸检测模型在 Raspberry Pi 上的表现进行性能评估。

人脸检测延迟时间对比
检测笑脸的整个流程(包括我们之前提到的三个步骤)平均耗时 48.1ms 并只使用一个线程,这意味着我们能够实现实时笑脸检测。
人脸检测
我们的人脸检测模型由定制的 8 位 MobileNet v1 模型和深度乘数为 0.25 的 SSD-Lite 模型所构成。其大小略大于 200KB。为什么这个模型这么小?第一,基于 Flatbuffer 的 TensorFlow Lite 模型大小比基于 Protobuf 的 TensorFlow 模型小。第二,我们采用 8 位量化模型。第三,我们的 MobileNet v1 经过改良,通道比原来更少。
与大多数人脸检测模型类似,模型会输出边界框和 6 个面部关键特征点(包括左眼、右眼、鼻尖、嘴部中心、左耳屏点和右耳屏点)的坐标。我们还应用了非极大值抑制 (Non-Maximum Suppression) 来过滤重复的人脸。人脸检测 TensorFlow Lite 模型的推理时间约为 30 毫秒。这意味着模型可以在 Raspberry Pi 上实现实时检测人脸。

边界框和 6 个面部关键特征点示例
人脸裁剪工具
检测到的人脸朝向和尺寸大小各不相同,为了统一并更好地进行分类,我们会旋转、裁剪和缩放原始图像。我们将从人脸检测模型中获得的 6 个面部关键特征点的坐标输入函数。通过这 6 个面部关键特征点,我们便可以计算出旋转角度和缩放比例。经过上述流程后,我们便可得到 128×128 的标准人脸图片。下图示例展示我们面部裁剪工具的功能。蓝色边界框是人脸检测模型的输出结果,而红色边界框是我们经计算得出的裁剪边界框。我们会复制图像外部的像素边界线。

人脸裁剪工具图示
人脸属性分类
我们的人脸属性分类模型也是 8 位量化 MobileNet 模型。将 128×128 的标准人脸输入该模型,其会输出介于 0 到 1 的浮点型变量用于预测微笑的概率。该模型也会输出 90 维向量来预测年龄,范围在 0 到 90 之间。其在 Raspberry Pi 上的推理时间可以达到 30 毫秒左右。
如何识别语音命令?
实时语音命令识别也可以分为三个步骤:
预处理:我们使用滑动窗口来储存最新的 1 秒音频数据,以及音频所对应的 512 帧图像。
推理:通过输入的 1 秒音频,我们可以应用语音命令模型来获得出现以下四种类别的概率(“是”/“否”/“无声”/“未知”)。
后期处理:我们通过当前的推理结果与先前的结果计算出平均值。当一个词语的平均出现概率高于某个阈值时,我们便判断已检测到语音命令。
我会在下文详细解释这三个步骤。
预处理
我们使用 PortAudio(一个开源代码库)获取来自麦克风的音频数据。下图展示我们如何储存音频数据。
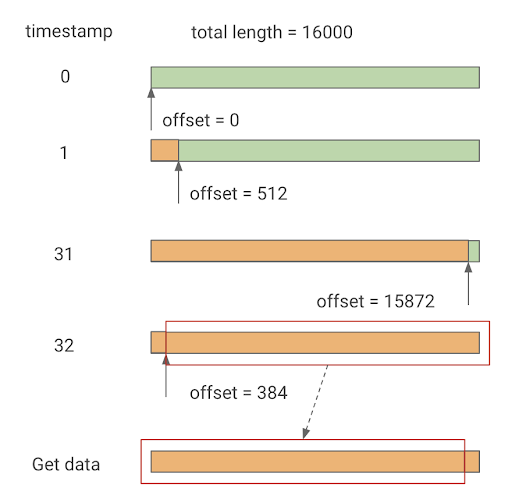
音频流处理
由于我们的模型使用采样率为 16kHz 的 1 秒音频数据进行训练,因此数据缓冲区的大小为 16,000 字节。数据缓冲区亦作为循环缓冲区使用,我们每次会更新对应的 512 帧。此外,我们还会记录偏移量,用于指明上次更新的结束位置。当缓冲区尾部已满时,我们会从缓冲区的头部继续操作。在我们想要获取音频数据来展开推理时,我们会从偏移处开始读取,然后在偏移结束对应的帧结束。
语音命令识别
您可在许多公开的 TensorFlow 示例中找到我们使用的语音命令识别模型。该模型由 audio_spectrogram、MFCC、2 个卷积层和 1 个全连接层组成。这个模型的输入内容为采样率为 16kHz 的 1 秒音频数据。数据集支持公开访问,或者您也可自行训练。此数据集包含 30 种语音命令数据。由于我们只需要“是”和“否”类别,所以我们将其他标记归类为“未知”。
此外,我们也采用了其他方法来缩短延迟时间:
我们去除半数通道。压缩后的TensorFlow Lite 模型大小约为 1.9 MB。
与通常情况下使用最后一个全连接层的 12 个输出通道有所不同,由于我们只需要 4 种类别,所以我们使用了其中 4 个输出通道。
我们使用多线程来进行推理。
在训练中,我们将背景音量设置成 0.3,以提高模型的抗噪能力。我们还将“无声”和“未知”类别的比例各设置成 25%,以平衡训练集。
后期处理
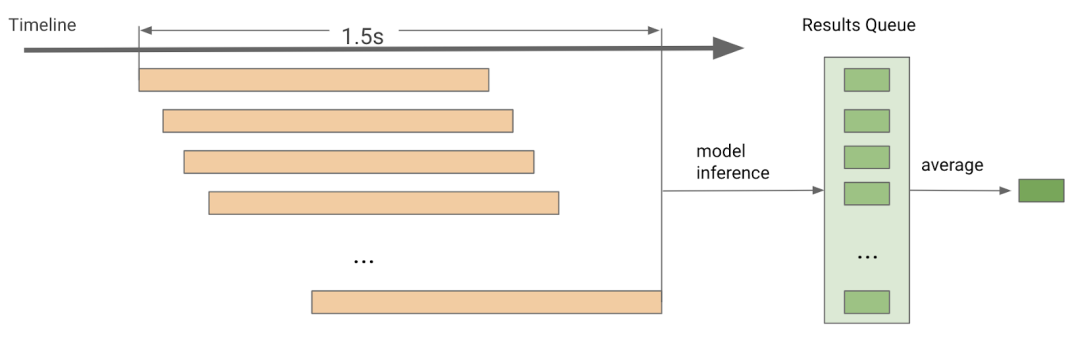
音频流后期处理
由于我们获取的音频数据可能仅截取到一半命令,所以单个预测结果并不准确。我们储存先前结果(之前的记录时间不长于 1.5s),以取得平均预测结果。这可以大大提高关键字检测的实时性能。我们能够保存的先前结果的数量,在很大程度上取决于我们的推理时间。例如,我们模型在 Raspberry Pi 上的推理时间约为 160 毫秒,这意味着我们最多可以保存 9 个先前结果。
后续行动
我们希望在 TensorFlow Lite Github 代码库中尽快开放这个示例的源代码。如要了解关于如何上手使用 TensorFlow Lite 的更多详情,请参阅此处,并在此处查看其他参考示例。
参阅此处。
请告诉我们您的想法或与我们分享您的 TensorFlow Lite 用例。
致谢
感谢 Lucia Li、Renjie Liu、Tiezhen Wang、Shuangfeng Li、Lawrence Chan、Daniel Situnayake、Pete Warden。
原文:https://mp.weixin.qq.com/s/8zD3GqbQrQnZmuD59OoFuQ
https://tensorflow.google.cn/lite/guide

好文啊,这么好的技术文章竟然没人评论
主要是没开源呀。